🧬 Autonomous and Non-Autonomous AI Systems, Part 1: Human-in-the-Loop (HITL)
Your AI Looks Autonomous. It’s Not. Here’s the Architecture Diagram to Prove It.
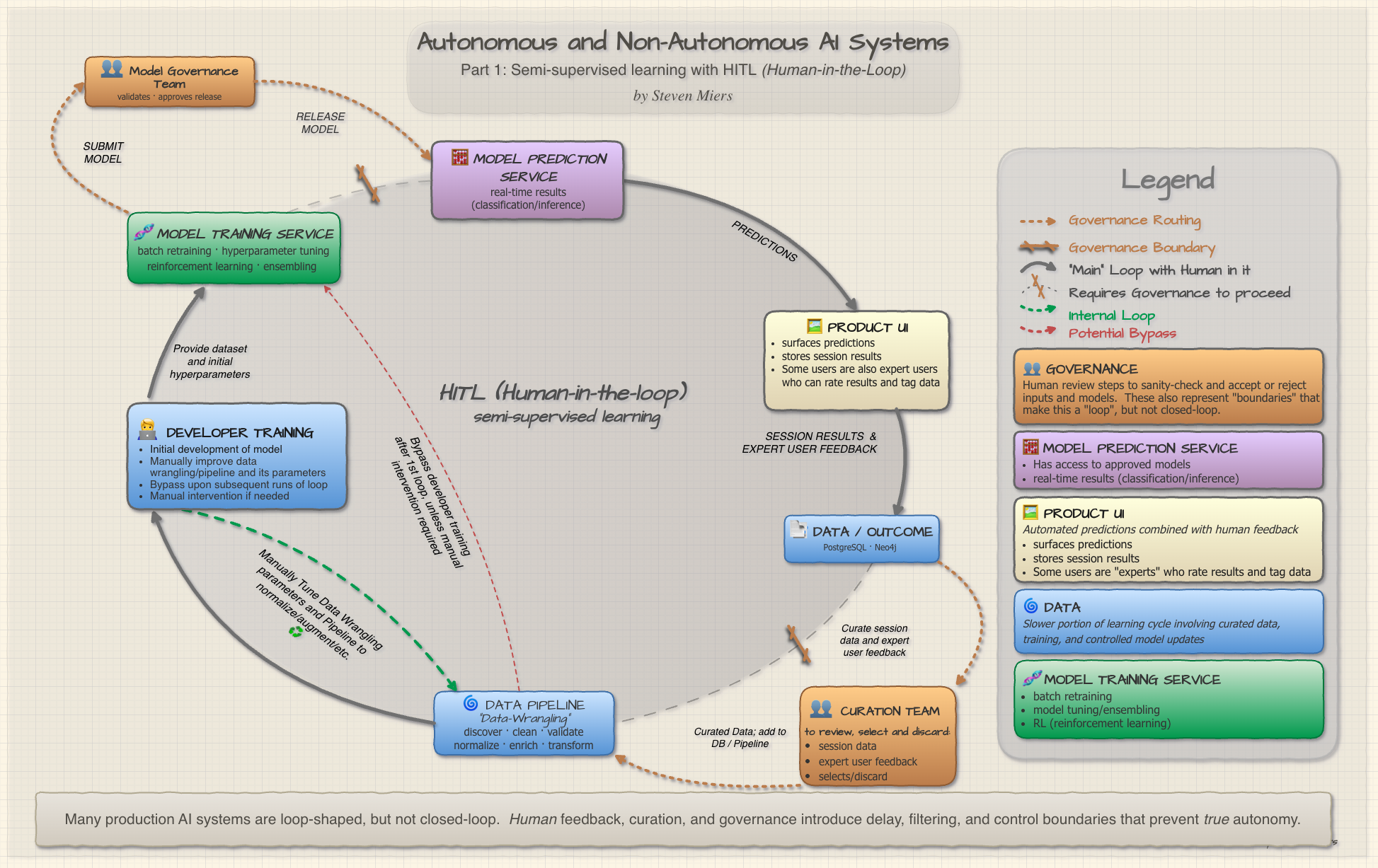
“Many production AI systems are loop-shaped, but not closed-loop. Human feedback, curation, and governance introduce delay, filtering, and control boundaries that prevent true autonomy.” — Author
🔃 The Illusion of the Closed Loop
Your platform performs specialized matching for clients. An ML model scores candidates, ranks them, and serves predictions through an API. The product team calls it “AI-powered.” The sales deck says “autonomous matching engine.” The investors nod approvingly.
Then you look at the actual architecture and notice:
- A human reviews every session before feedback enters the training set
- A governance team approves every model before it touches production
- The “real-time learning” happens in a batch job that runs Tuesday nights
Congratulations. You’ve built a very sophisticated suggestion box with a neural network attached.
This isn’t a criticism — it’s a classification. Most production AI systems that look autonomous are actually Human-in-the-Loop (HITL) systems. They’re adaptive, useful, and often excellent. But they are not closed-loop.
Understanding why matters, because the architecture you choose determines what your system can and cannot learn, how fast it can learn it, and who’s liable when it gets something wrong.
👥 What Makes a System HITL?
A HITL system is one where humans are structurally embedded in the feedback and control pathways of the AI. Not as end users consuming predictions, but as active mediators of what the system learns and how it evolves.
The key structural signatures are:
| Signature | What It Means |
|---|---|
| Human-mediated feedback | Expert users rate, tag, or correct predictions — but the signal is filtered before reaching training |
| Delayed learning | Models retrain on curated batches, not streaming feedback |
| Filtered signal | A curation team selects which feedback enters the training pipeline |
| Controlled deployment | A governance team validates and approves model releases |
If your system has any of these, it’s HITL. If it has all four, it’s what I’d call fully-mediated HITL — the human isn’t just in the loop, they are the loop’s bottleneck.
🏛️ The Architecture: HITL Loop and Governance Overlays
The infographic below maps HITL architecture as an elliptical loop with governance overlays shown where the loop is “broken”.
⬭ The HITL System
This is the main human-in-the-loop. Predictions flow to users, users react, reactions get stored.
It is NOT a closed loop in that there is a data curation team and a model governance team marked with “GOVERNANCE”.
- 🧮 MODEL PREDICTION SERVICE: real-time results (classification/inference)
- 🖼️ PRODUCT UI: Automated predictions combined actual session info and expert user feedback
- 📑 DATA / OUTCOME: Storage of session outcome and expert user feedback
- 👥 CURATION TEAM (GOVERNANCE):
- Evaluates user session data and feedback from expert user
- Select for inclusion or exclusion (or include with changes)
- Sanity-check
- 🌀 DATA PIPELINE: (Data-Wrangling)
- Discover
- Validate
- Clean
- Normalize
- Enrich/Augment/Transform
- 🧑💻 DEVELOPER TRAINING
- Initial development of model
- Bypassed in subsequent loops
- Can be done again for manual intervention, to change wrangling parameters, for normalization, augmentation, etc.
- 🧬 MODEL TRAINING SERVICE
- batch retraining
- model tuning/ensembling
- RL (reinforcement learning)
- 👥 MODEL VERIFICATION TEAM (GOVERNANCE):
- QA of new model
- Sanity check
⛓️💥Governance Overlays: The Human Gatekeepers
At the top-left and bottom-right are two governance boundaries (shown as dashed orange flows and orange boxes in the infographic):
- Store → Curation Team → Pipeline: A curation team reviews session data and selects which signals are trustworthy enough for training. This prevents noisy or adversarial feedback from corrupting the model.
- Model Ensemble → Model Governance Team → Deployment: A governance team validates model performance, checks for bias, and approves releases. No model reaches production without human sign-off.
These aren’t bureaucratic overhead. They’re architectural control surfaces. Remove them, and your “AI-powered” system is one bad training batch away from recommending your worst matches for your best client.
The Problem Domain: Matching
This architecture isn’t theoretical. It maps to production systems in the professional services space — platforms where the cost of a bad match is measured in lost contracts, not lost clicks.
Matching requires:
- 📐 Precision: The difference between “knows about derivatives” and “structured credit derivatives at a bulge-bracket bank during the 2008 crisis” is the difference between a usable match and a wasted hour.
- 🧭 Context: The same match might be perfect for a diligence call and terrible for a survey. Context isn’t just who — it’s why, when, and for whom (and even where).
- ♻️ Continuous improvement: Match availability, knowledge of end-users and expert users, and client preferences all drift. A static model degrades visibly within weeks.
This combination — high precision, rich context, continuous drift — naturally produces semi-supervised systems. You can’t label everything (too expensive), you can’t leave everything unlabeled (too noisy), so you build a system where humans and models collaborate. That’s HITL.
🤖 Why It’s Not Autonomous (And Why That’s Fine)
A truly autonomous system would:
- Ingest feedback directly into the learning loop without human curation
- Retrain continuously (or near-continuously) on streaming data
- Deploy updated models automatically based on performance thresholds
- Self-correct without human intervention when predictions degrade
Our HITL system does none of these. Every feedback signal passes through at least one human filter. Retraining is batched. Deployment is gated. Correction requires a human to notice the problem, diagnose it, and intervene.
🏦 Autonomy Debt
And that’s often the right call. Fully autonomous systems can fail fast and fail weird. HITL systems fail slow and fail in ways humans can understand and fix. In a domain where a single catastrophic match can lose a client relationship worth millions, a HITL system may be a better choice than a closed-loop system.
The tradeoff is “Autonomy Debt”: the gap between what your system could learn if it were fully autonomous and what it actually learns given human bandwidth constraints.
🚰 Bottleneck
As your network of matchable items scales from hundreds to tens of thousands, the curation team becomes the bottleneck . The governance review becomes the deployment blocker. The humans who make the system trustworthy also make it slow.
Managing that debt — knowing when to automate a gate, when to keep a human in the loop, and when to add more humans — is the central architectural challenge of HITL systems.
🧠 Semi-Supervised Learning in Practice
The HITL architecture naturally implements a semi-supervised learning pattern. Here’s how it breaks down:
| Component | Supervised Signal | Unsupervised Signal |
|---|---|---|
| Expert user Ratings and Tagging | Explicit tagging and evaluation on matches | — |
| User Session outcomes | — | Engagement metrics (attempts, total time to find match, sequence in result list, etc.) |
| Data Curation | Curated training labels and data to improve matching | — |
| Model Curation | Evaluated and approved models for use in inference | — |
The supervised signal is expensive (human-generated) and sparse. The unsupervised signal is cheap and abundant. The semi-supervised architecture lets you use the abundant signal to expand coverage while using the expensive signal to maintain quality.
This is exactly the pattern described in Zhu & Goldberg’s foundational work on semi-supervised learning — using a small amount of labeled data to guide learning from a large amount of unlabeled data. In a HITL system, the “labeling” happens through the operational loop, and the “guidance” happens through the governance overlay.
🗝️ Key Takeaways
Many production AI systems are loop-shaped, but not closed-loop. Human feedback, curation, and governance introduce delay, filtering, and control boundaries that prevent true autonomy.
This is Part 1 of a series. In Part 2, we’ll look at what happens when you start removing those human gates — Autonomous AI Systems — and the entirely different failure modes that emerge when the loop actually closes.
📖 References
-
Zhu, Xiaojin & Goldberg, Andrew B. Introduction to Semi-Supervised Learning. Morgan & Claypool, 2009. — Foundational framework for combining labeled and unlabeled data.
-
Monarch, Robert. Human-in-the-Loop Machine Learning. Manning Publications, 2021. — Comprehensive treatment of HITL patterns in production ML systems.
-
Christiano, Paul, et al. “Deep Reinforcement Learning from Human Feedback.” NeurIPS, 2017. — The RLHF paradigm that underpins modern HITL training loops.
-
Amershi, Saleema, et al. “Software Engineering for Machine Learning: A Case Study.” ICSE-SEIP, 2019. — Microsoft’s production ML lifecycle patterns, including human oversight gates.
-
Sculley, D., et al. “Hidden Technical Debt in Machine Learning Systems.” NeurIPS, 2015. — The foundational paper on ML systems debt, directly relevant to Autonomy Debt.
Steven Miers — git-steven.github.io
